DegreeGuru: Build a RAG Chatbot using Vercel AI SDK, Langchain, Upstash Vector and OpenAI

Welcome to this blog post, where we will talk about the inception and evolution of the DegreeGuru chatbot application utilizing Retrieval Augmented Generation (RAG) approach. Here, we delve into the motivations that sparked its creation, tracing its development through the web of tools such as Upstash Vector, Upstash Redis, Langchain, Next.js, Vercel, and the Vercel AI SDK.
Following the exploration of our motivations, we will discuss our approach and the requirements that guided our development process. Subsequently, we provide an overview of the tech stack employed. In the following sections, we delve into the implementation of the crawler and the DegreeGuru app.
Motivation
Consider a future master's student, exploring various university programs. Picture her quest for vital details: application deadlines, submission methods—online or by mail, admission criteria, and program specifics.
However, the websites of different universities seem worlds apart. They vary immensely in design and how information is organized, making the search for required details a difficult task.
Imagine if there was a simpler method to access information on these websites! Enter DegreeGuru: a chatbot that can be easily tailored to any website, in under an hour. Including this innovative tool in the university webpages will empower our master's student, providing her with the specific information she seeks, all through a user-friendly chat interface.
Approach & Requirements
In developing the DegreeGuru chatbot application, our focus was on creating a seamless user experience while ensuring the accuracy and reliability of information provided. Here is an overview of the key requirements we considered in the development process:
- Simple Interface: Should offer users a straightforward and user-friendly interface.
- Streaming Responses: Instead of waiting for the Large Language Model (LLM) to generate the entire response before sending it to the user, we should stream tokens as they are generated using Vercel AI SDK. This means users get to see partial responses in real-time, creating a more dynamic conversation flow.
- Reliable Source Attribution: Answers should include links to the sources of the information. This approach ensures reliability, allowing users to verify the information themselves.
- Data Collection: To populate the Upstash Vector Store with relevant information, there should be an easy-to-configure scraper. The scraper should split the page contents into chunks and store them in the Upstash Vector Store after fetching their vector embeddings.
- Configurability: The crawler and the app should be domain agnostic, meaning it should easily be configured for use on any website, not limited to universities.
To ensure we include links to the sources of information, we instruct the agent to use the URLs of the corresponding text chunks during response generation. These URLs, indicating the origin of the text, are stored as metadata together with the vectors in the Upstash Vector Store. When a user submits a query, we include these URLs in the context provided to the LLM agent.
Combined with our data collection process, we claim that by following our guide on deploying your own DegreeGuru app, you will be able to deploy a chatbot for any website in under an hour!
Tech Stack
| Usage | Technology | |--------------------|------------------------------------------------------| | Crawler | scrapy | | Chatbot App | Next.js | | Vector DB | Upstash Vector | | LLM Orchestration | Langchain.js | | Generative Model | OpenAI, gpt-3.5-turbo-1106 | | Embedding Model | OpenAI, text-embedding-ada-002 | | Text Streaming | Vercel AI | | Rate Limiting | Upstash Redis |
Implementation
In the following subsections, we delve into how of our crawler and the DegreeGuru app works.
Crawler
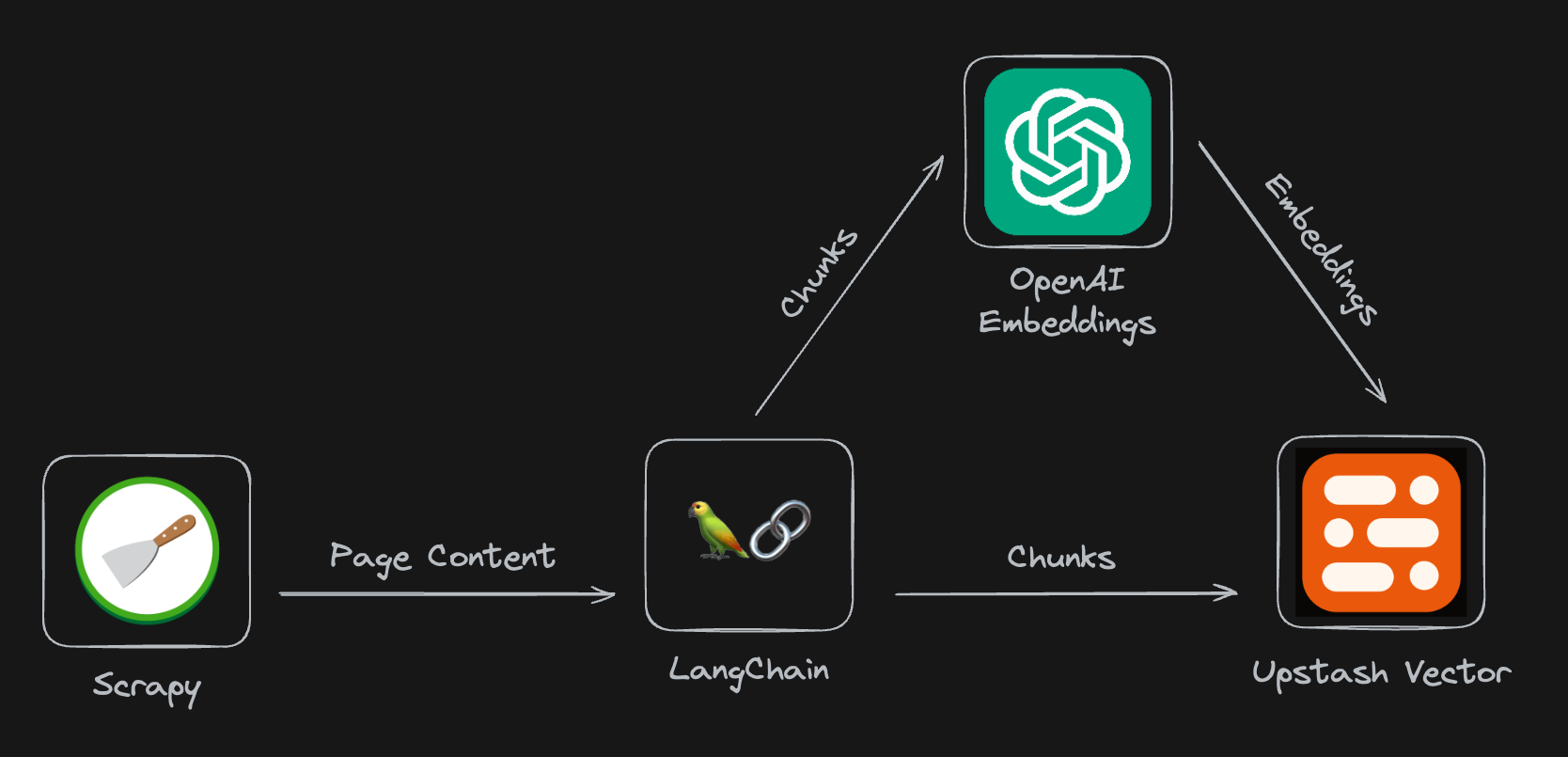
At the core of any chatbot lies its data. In our case, we want to use websites as the source of data. To collect data from the desired websites, we employ a custom Scrapy spider.
Setting up a Scrapy Project
First step of creating a Scrapy crawler is to setup a new Scrapy project with (see Scrapy documentation):
scrapy startproject degreegurucrawler
This command sets up a scrapy project under the degreegurucrawler directory. In this directory there is a spiders directory, which is where we will write our spider.
Configuration
One of the requirements in our project is to have a simple way of populating the Upstash Vector. To this end, we have created a crawler.yaml file. Through this file, we can configure:
- which urls our spider will start crawling from
- which links our link extractor will match
- which OpenAI embeddings model will be used when creating embeddings from chunks
- parameters with which our
RecursiveCharacterTextSplitterwill split the content of a webpage into text chunks
# degreegurucrawler/utils/crawler.yaml
crawler:
start_urls:
- https://www.some.domain.com
link_extractor:
allow: '.*some\.domain.*'
deny:
- "#"
- '\?'
- course
- search
- subjects
index:
openAI_embedding_model: text-embedding-ada-002
text_splitter:
chunk_size: 1000
chunk_overlap: 100You can find more information about configuring the crawler in our guide.
Vector Store
We rely on the Upstash Vector for storing vectors and metadata. Setting up an Upstash Vector Store is very simple, akin to flipping a switch: Simply head to the Upstash Console, access your account, select "Vector" from the navigation bar, and create an index with the click of a button labeled "Create Index". For further instructions, delve into the "Configure Environment Variables" section of our guide.
Next, we add the UpstashVectorStore class to handle embedding text chunks and storing them in the Upstash Vector.
# degreegurucrawler/utils/upstash_vector_store.py
from typing import List
from openai import OpenAI
from upstash_vector import Index
class UpstashVectorStore:
def __init__(
self,
url: str,
token: str
):
self.client = OpenAI()
self.index = Index(url=url, token=token)
def get_embeddings(
self,
documents: List[str],
model: str = "text-embedding-ada-002"
) -> List[List[float]]:
"""
Given a list of documents, generates and returns a list of embeddings
"""
documents = [document.replace("\n", " ") for document in documents]
embeddings = self.client.embeddings.create(
input = documents,
model=model
)
return [data.embedding for data in embeddings.data]
def add(
self,
ids: List[str],
documents: List[str],
link: str
) -> None:
"""
Adds a list of documents to the Upstash Vector Store
"""
embeddings = self.get_embeddings(documents)
self.index.upsert(
vectors=[
(
id,
embedding,
{
"text": document,
"url": link
}
)
for id, embedding, document
in zip(ids, embeddings, documents)
]
)Note that in the UpstashVectorStore.add() method, we pass the a list of tuples as the vectors parameter. Third item in each tuple is the metadata of our vector. In the metadata, we pass a dictionary with two fields: text and url. url field denotes the URL of the website text was read from. Including the URL in metadata allows us to feed this information to the LLM agent later.
Spider
Finally, we define our configurable spider, appropriately named ConfigurableSpider. The ConfigurableSpider consumes configuration defined in crawler.yaml to create a spider:
# degreegurucrawler/spiders/configurable.py
import os
import uuid
import logging
from ..utils.upstash_vector_store import UpstashVectorStore
from ..utils.config import text_splitter_config, crawler_config
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from langchain.text_splitter import RecursiveCharacterTextSplitter
class ConfigurableSpider(CrawlSpider):
name = "configurable"
start_urls = crawler_config["start_urls"]
rules = (
Rule(
LinkExtractor(
**crawler_config["link_extractor"]
),
callback="parse_page",
follow=True # to enable following links on each page when callback is provided
),
)
def __init__(self, *a, **kw):
super().__init__(*a, **kw)
self.vectorstore = UpstashVectorStore(
url=os.environ.get("UPSTASH_VECTOR_REST_URL"),
token=os.environ.get("UPSTASH_VECTOR_REST_TOKEN")
)
print(
f"Creating a vector index at {os.environ.get('UPSTASH_VECTOR_REST_URL')}.\n"
f" Vector store info before crawl: {self.vectorstore.index.info()}"
)
self.text_splitter = RecursiveCharacterTextSplitter(
**text_splitter_config
)
self._disable_loggers()
# ...
def parse_page(self, response):
"""
Creates chunks out of the crawled webpage and adds them to the vector
store.
"""
# extract text content
text_content = response.xpath('//p').getall()
text_content = '\n'.join(text_content)
# split documents
documents = self.text_splitter.split_text(text_content)
if len(documents) == 0:
return
# get source url
link = response.url
# add documents to vector store
self.vectorstore.add(
ids=[str(uuid.uuid4())[:8] for doc in documents],
documents=documents,
link=link
)The ConfigurableSpider.parse_page method is where all the magic happens. The response parameter has two attributes url which provides us the url and xpath which provides the content of the crawled webpage.
To extract the content of the page, we use response.xpath('//p'), which retrieves every element on the page with a <p> tag in HTML format. We chose HTML format to retain any <a> tags within these <p> elements, ensuring DegreeGuru has access to hyperlink information on the webpages. Using HTML could impact the reliability of our vectors, but we have seen in our experiments that the embedding models are able to handle the additional complexity.
After fetching the webpage content, we split into text chunks and add them to the Upstash Vector.
Running Crawler
After configuring the crawler and setting up the environment as explained in our guide, we can finally run the crawler:
scrapy crawl configurable --logfile degreegurucrawl.log
Once set up and run, the crawler will take some time as it crawls the website as configured and populates our vector store. While waiting for the crawler to finish, we can delve into how the DegreeGuru app works!
DegreeGuru
DegreeGuru is a web application utilizing Retrieval Augmented Generation (RAG) approach and an OpenAI Large Language Model (LLM) to answer questions. Our Upstash Vector is provided to an LLM agent as a retriever "tool". Upon user prompt, the LLM agent fetches relevant context from the Upstash Vector Store and uses it to answer the user question.
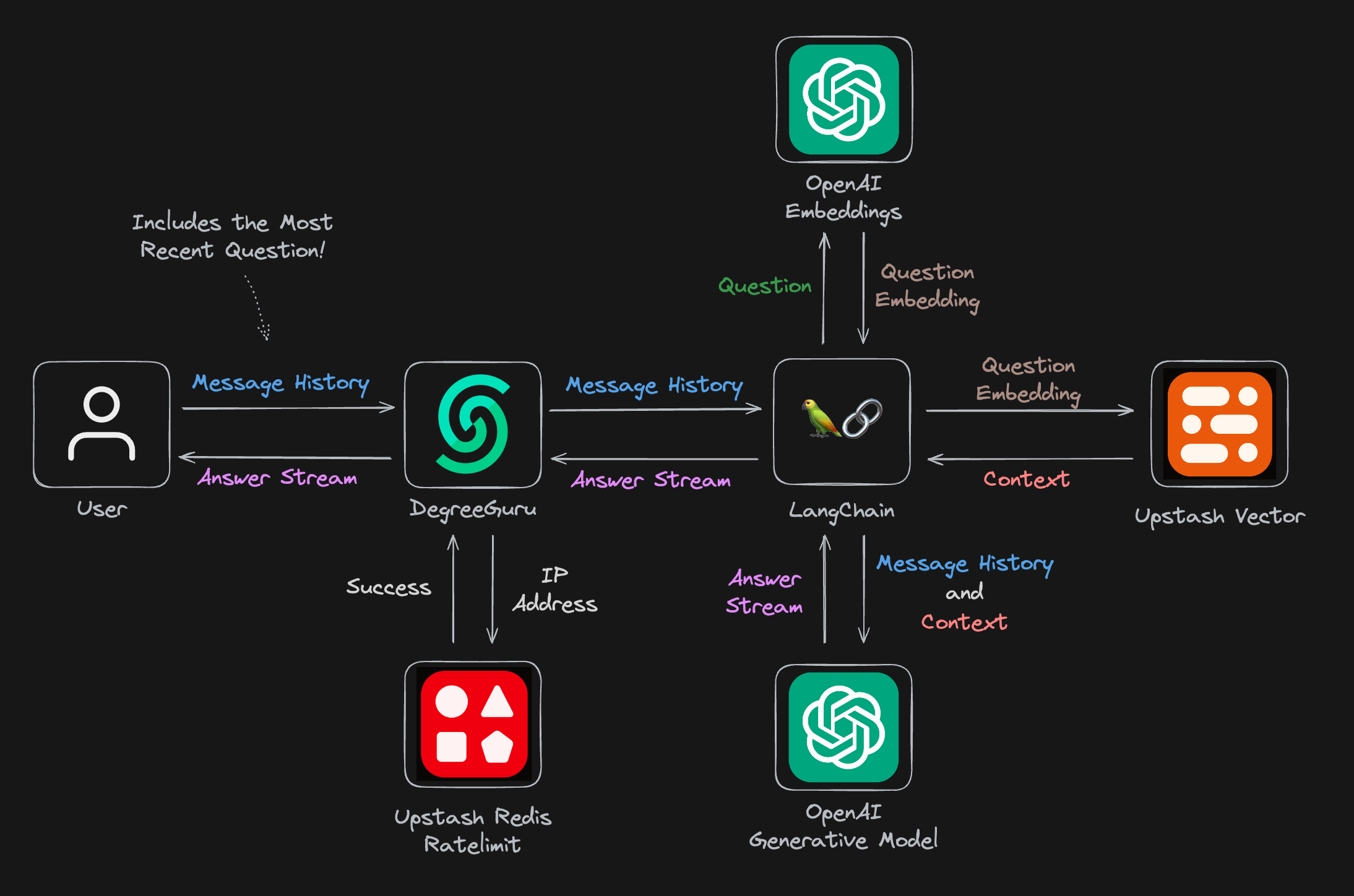
Here is how DegreeGuru operates at a high level: The /api/guru endpoint is invoked with the user's message history, including their most recent message. The application then employs Upstash Redis to verify if the IP source of the request is subject to rate limiting. If not restricted, our chatbot proceeds to generate a response. Initially, the question's embedding is computed, which is subsequently utilized to extract context from the Upstash Vector Store. Finally, both the message history and extracted context are fed into the generative model to produce the response, which is promptly streamed back to our user. For more details, see the route.tsx file where the endpoint is defined.
In the following sections, we will explain:
- How the Retrieval Augmented Generation (RAG) approach workds
- How we utilize Upstash Redis to limit access rate to our app
- How we use the Upstash Vector as a retriever
- What we use as the agent template
- How we make use of
useChatfrom Vercel AI SDK for streaming LLM outputs to the users.
Retrieval Augmented Generation (RAG)
In the realm of conversational AI, the Retrieval Augmented Generation (RAG) approach has emerged as a powerful technique. RAG combines the strengths of both retrieval-based and generative models, offering a nuanced solution for chatbots. At its core, RAG leverages a retriever to search through a vast amount of data. This retrieved information then augments the generative model's ability to produce accurate responses. In our project, we implement RAG with the Upstash Vector serving as the retriever.
Rate Limiting
Rate limiting in the context of the chatbot serves as a crucial cost management strategy. Each interaction with the chatbot has a cost, not only through the utilization of OpenAI credits but also by triggering Upstash Vector, which follows a pay-per-usage model.
For rate limiting, we use Upstash Redis. Setting up a rate limiter is as easy as installing @upstash/ratelimit and @upstash/redis packages and initializing a rate limiter like below:
// app/api/guru/route.js
import { Ratelimit } from "@upstash/ratelimit";
import { Redis } from "@upstash/redis";
// ...
const redis = Redis.fromEnv();
const ratelimit = new Ratelimit({
redis: redis,
limiter: Ratelimit.slidingWindow(1, "10 s"),
});
// ...
export async function POST(req: NextRequest) {
try {
const ip = req.ip ?? "127.0.0.1";
const { success } = await ratelimit.limit(ip);
if (!success) {
const textEncoder = new TextEncoder();
const customString =
"Oops! It seems you've reached the rate limit. Please try again later.";
const transformStream = new ReadableStream({
async start(controller) {
controller.enqueue(textEncoder.encode(customString));
controller.close();
},
});
return new StreamingTextResponse(transformStream);
}
// ...
}
}The user is shown an information message when their request is denied because the rate limit was reached.
Upstash Vector Store
A crucial component of our app is the Upstash Vector Store. Here is how we create one to create a retriever tool:
// app/api/guru/route.js
// Upstash VectorStore as retriever
const vectorstore = await new UpstashVectorStore(new OpenAIEmbeddings());
const retriever = vectorstore.asRetriever();
// retriever tool
const tool = createRetrieverTool(retriever, {
name: "search_latest_knowledge",
description: "Searches and returns up-to-date general information.",
});Agent Template
In the development of any chatbot, defining the agent template is a critical step. In our agent template, the bot is designated as "DegreeGuru", specializing in answering inquiries about Stanford University. The template instructs the bot to respond exclusively to questions based on available context, and encourages the use of relevant links whenever possible.
// app/api/guru/route.js
const AGENT_SYSTEM_TEMPLATE = `
You are an artificial intelligence university bot named DegreeGuru, programmed to respond to inquiries about Stanford in a highly systematic and data-driven manner.
Your responses should be precise and factual, with an emphasis on using the context provided and providing links from the context whenever posible. Begin your answers with a formal greeting and sign off with a closing statement about promoting knowledge.
Reply with apologies and tell the user that you don't know the answer only when you are faced with a question whose answer is not available in the context.
`;Streaming with useChat
Ensuring a seamless user experience is a key focus of our project. To achieve this, we use streaming to deliver Large Language Model (LLM) outputs to users as they are generated. We added this functionality through the use of the useChat utility from the Vercel AI SDK.
The useChat utility provides essential functionalities for our project. With initialMessages, we can start the app with a welcoming message from the bot. onResponse allows us to define a function to be called when the stream ends. We call the setInput method if the user clicks a suggested question on the chat interface.
// page.tsx
import React, { useEffect, useRef, useState } from "react";
import { Message as MessageProps, useChat } from "ai/react";
// ...
export default function Home() {
// ...
const [streaming, setStreaming] = useState<boolean>(false);
const { messages, input, handleInputChange, handleSubmit, setInput } =
useChat({
api: "/api/guru",
initialMessages: [
{
id: "0",
role: "system",
content: `**Welcome to DegreeGuru**
Your ultimate companion in navigating the academic landscape of Stanford.`,
},
],
onResponse: () => {
setStreaming(false);
},
});
// ...
}Running DegreeGuru
After installing packages with npm install and configuring the environment variables as explained in our guide, you can run npm run dev to start the app in your local environment. No need to wait for the crawler to finish. You can dive right in and start asking questions!
Deploying to Vercel
Once you've finished populating your vector store, deploying the chatbot with Vercel is very simple. Should you choose to crawl a source other than Stanford, we suggest modifing our agent template accordingly. This can be done by forking our repository, making the necessary updates to the template, and finally clicking the "Deploy" button located at the top of the README file within your forked repository to launch the app on Vercel.
Conclusion
Through the integration of tools such as Upstash Vector, Redis, Langchain, Next.js, and Vercel, we have crafted a useful proof of concept. The DegreeGuru, utilizing the Retrieval Augmented Generation (RAG) approach, enables users with swift access to information, all within a user-friendly chat interface.
The ability to customize DegreeGuru to any website in under an hour opens doors for universities, businesses, and individuals alike. Imagine the ease with which our prospective student can now navigate the vast web of university program details, deadlines, and admission criteria. This same ease of access can be offered to the users of any website, using the DegreeGuru project.